© 2023 yanghn. All rights reserved. Powered by Obsidian
4.4. 模型选择、欠拟合和过拟合
要点
- K 折交叉验证的目的是通过多次平均,相对准确的评估模型在当前超参数下的好坏
1. 训练误差与泛化误差
训练误差(training error)是指,模型在训练数据集上计算得到的误差。
泛化误差(generalization error)是指,模型应用在新数据(测试集)(同样从原始样本的分布中抽取的无限多数据样本时),模型误差的期望。
验证数据集:一个用来选超参数的数据集,评估模型好坏,看是否过拟合
- 例如拿出 50% 的训练数据
- 不要跟训练数据混在一起(不要拿验证数据训练模型!)
- 验证数据集的精度会虚高,不代表新的数据集上的模型能力
注意
代码里常用 test set 表示验证数据集,虽然名字叫 test set,但实际上是 validation set
测试数据集:只用一次的数据集,报告模型性能
- 未来的考试(只能考一次的高考)
- Kaggle 私有排行榜数据集
2. K 折交叉验证
通常我们没有很多数据来训练,所以分给评估模型好坏的数据也很少;同时由于很多学习算法的随机性、初始值设置的随机性,需要多次验证来求平均,从而相对准确的反应模型好坏。
算法过程:
- 将训练数据分为 K块
- For i = 1,..., K
* 使用第 i 块当做验证集,其余当做训练集
* 计算误差 - 计算 K 次误差平均值,即为验证误差
一般来说 K = 5 或者 10,K 越大效果越好,但要训练 K 次,基于训练成本考量
注意
是拿同一个模型训练 K 次,计算这 K 次的平均误差,不是接着第一折训练数据,在第二折数据的基础上继续训练
3. 过拟合和欠拟合
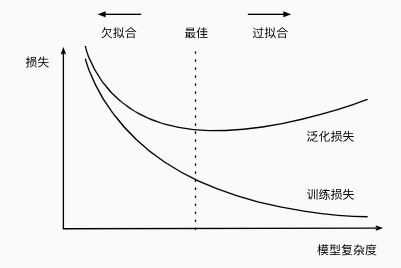
注意
这里横轴是模型复杂度,比如神经网络的深度,而课程 Notebook 里横轴是一个模型多次训练的训练次数
深度学习一个核心思路就是模型足够复杂,再去调整模型复杂度达到最优
思考:如何估计模型的复杂度
- 难以在不同的种类算法之间比较
- 例如树模型和神经网络
- 给定一个种类的模型,主要以下两个因素:
- 参数的个数
- 参数的选择范围
- VC 维
2. VC 维
用来衡量模型的复杂度,定义为:对于一个分类模型,VC 维等于一个最大数据集的大小,不管数据集的 target 怎么标号,这个模型都能完美分类
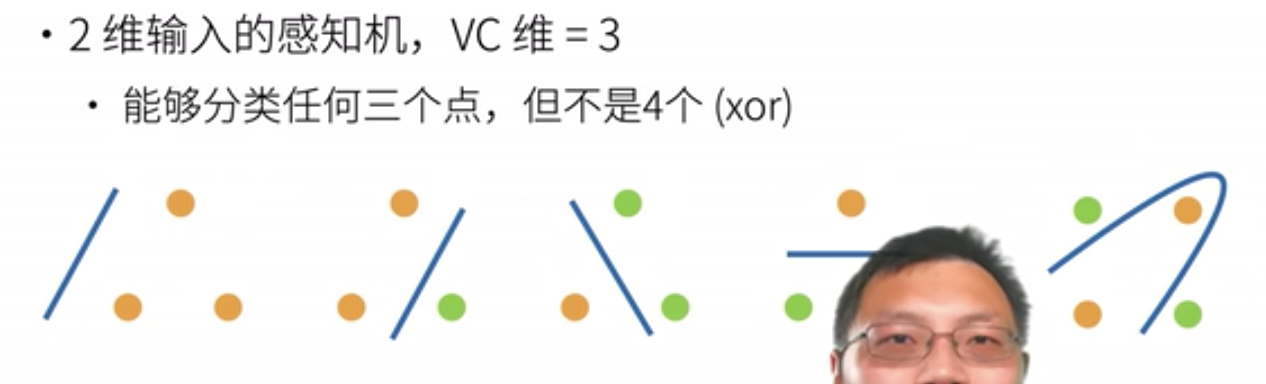
- N 维空间的感知机,VC 维为N+1
- N 维空间的多层感知机,VC 维为